
原文 2015-03-31 01:16:10 发表于 CSDN,这里对以前写的文章做下收录。
在说 erlang 异常捕获处理(catch)前,不得不说 erlang 内部数据(Eterm)。Eterm 是 Erlang Term 的简写,用来表示 erlang 中任意类型的数据,也就是说,erlang 可以用到的任意数据,都能 Eterm 表示。比如常见的 atom、数字、列表、元组,甚至 pid,port,fun,ets 表等等都用Eterm可以表示。
Eterm
Eterm 在 VM 中主要分为三大类:列表,boxed 对象,立即数。(这么分法主要是复杂的数据无法单靠1个机器字表示,在32位机器上,一个字长4字节,在64位机器上是8字节。)
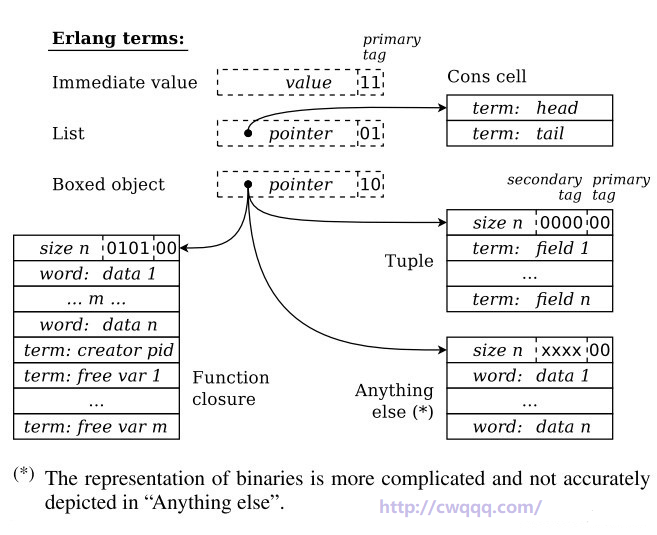
其中,boxed 对象表示了复杂数据类型,如元组,大整数,二进制等。而立即数表示的就是一些简单的小数据,如小整数,原子,pid 等。
但这里为什么会有catch?相信不少人都会有这样的疑问。所以,下文就围绕着 catch 做说明。
catch表达式
形式:catch Expr
如果 Expr执行过程没有异常发生,就返回Expr的执行结果。但如果异常发生了,就会被捕获。
1> catch 1+2.
3
2> catch 1+a.
{'EXIT',{badarith,[...]}}
3> catch throw(hello).
hello
catch立即数怎么产生的?
这个数据类型只在 Erlang VM 内部使用,Erlang 程序不会直接操作这个数据类型。当代码中含有 catch 或者 try-catch语句时就会产生catch,而且,这个数据将会被放置到 Erlang 进程的栈上。
源码分析
下面以一个简单做说明。
-module(test). -compile(export_all). t() -> catch erlang:now().
保存为test.erl,通过erlc -S test.erl 得到汇编代码 test.S,内容如下:
{function, t, 0, 2}.
{label,1}.
{line,[{location,"test.erl",4}]}.
{func_info,{atom,test},{atom,t},0}.
{label,2}.
{allocate,1,0}.
{'catch',{y,0},{f,3}}.
{line,[{location,"test.erl",5}]}.
{call_ext,0,{extfunc,erlang,now,0}}.
{label,3}.
{catch_end,{y,0}}.
{deallocate,1}.
return.
这里可以看到 catch 和 catch_end 是成对出现的。下面再编译成opcode吧,容易到VM代码中分析。
1> c(test).
{ok,test}
2> erts_debug:df(test).
ok
找到生成 test.dis,内容如下:
04B55938: i_func_info_IaaI 0 test t 0 04B5594C: allocate_tt 1 0 04B55954: catch_yf y(0) f(0000871B) 04B55960: call_bif_e erlang:now/0 04B55968: catch_end_y y(0) 04B55970: deallocate_return_Q 1
以上, allocate_tt 和 deallocate_return_Q 在 beam_hot.h 实现,其他在 beam_emu.c 实现,都可以找相关代码。
先看下这几个指令:
// beam_emu.c
OpCase(catch_yf):
c_p->catches++; // catches数量加1
yb(Arg(0)) = Arg(1); // 把catch指针地址存入进程栈,即f(0000871B)
Next(2); // 执行下一条指令
// beam_emu.c
OpCase(catch_end_y): {
c_p->catches--; // 进程 catches数减1
make_blank(yb(Arg(0))); // 将catch立即数的值置NIL,数据将会丢掉
if (is_non_value(r(0))) { // 如果异常出现
if (x(1) == am_throw) { // 如果是 throw(Term),返回 Term
r(0) = x(2);
} else {
if (x(1) == am_error) { // 如果是 error(Term), 再带上当前堆栈的信息
SWAPOUT;
x(2) = add_stacktrace(c_p, x(2), x(3));
SWAPIN;
}
/* only x(2) is included in the rootset here */
if (E - HTOP < 3 || c_p->mbuf) { /* Force GC in case add_stacktrace()
* created heap fragments */
// 检查进程堆空间不足,执行gc避免出现堆外数据
SWAPOUT;
PROCESS_MAIN_CHK_LOCKS(c_p);
FCALLS -= erts_garbage_collect(c_p, 3, reg+2, 1);
ERTS_VERIFY_UNUSED_TEMP_ALLOC(c_p);
PROCESS_MAIN_CHK_LOCKS(c_p);
SWAPIN;
}
r(0) = TUPLE2(HTOP, am_EXIT, x(2));
HTOP += 3;
}
}
CHECK_TERM(r(0));
Next(1); // 执行下一条指令
}
//beam_hot.h
OpCase(deallocate_return_Q):
{
DeallocateReturn(Arg(0));//释放分配的栈空间,返回上一个CP指令地址
}
注:CP是返回地址指针
DeallocateReturn实际是个宏,代码如下:
#define DeallocateReturn(Deallocate) \
do { \
int words_to_pop = (Deallocate); \
SET_I((BeamInstr *) cp_val(*E)); \ // 解析当前栈的指令地址,
E = ADD_BYTE_OFFSET(E, words_to_pop); \ // 即获取上一个CP指令地址
CHECK_TERM(r(0)); \
Goto(*I); \ //执行的指令
} while (0)
到这里,应该有同学开始疑惑了。这里说的catch ,真是前面提到的 catch立即数吗?
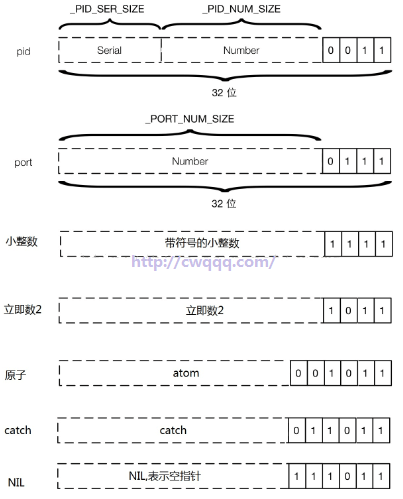
谈到 catch 立即数,很多同学可以找到以下这两个宏:
// erl_term.h #define make_catch(x) (((x) << _TAG_IMMED2_SIZE) | _TAG_IMMED2_CATCH) // 转成catch立即树 #define is_catch(x) (((x) & _TAG_IMMED2_MASK) == _TAG_IMMED2_CATCH) // 是否catch立即数
这两个是 catch 立即数的生成和判定,后面的代码会提到这两个宏的使用。
现在,我们来看下 VM 解析和加载 catch 代码的过程:
// beam_load.c 加载beam过程,有删节
static void final_touch(LoaderState* stp){
int i;
int on_load = stp->on_load;
unsigned catches;
Uint index;
BeamInstr* code = stp->code;
Module* modp;
/*
* 申请catch索引,填补catch_yf指令
* 前面的f(0000871B)就在这里产生的,指向了beam_catches结构数据
* 因为一个catch立即数放不了整个beam_catches数据,就只放了指针
*/
index = stp->catches;
catches = BEAM_CATCHES_NIL;
while (index != 0) { //遍历所有的catch_yf指令
BeamInstr next = code[index];
code[index] = BeamOpCode(op_catch_yf); // 指向catch_yf指令的opcode地址
// 获取 catch_end 指令地址,构造beam_catches结构数据
catches = beam_catches_cons((BeamInstr *)code[index+2], catches);
code[index+2] = make_catch(catches); //将beam_catches索引位置转成catch立即数
index = next;
}
modp = erts_put_module(stp->module);
modp->curr.catches = catches;
/*
* 删节....
*/
}
再来看下什么时候会执行到 这里的代码。
细心的同学就会发现,VM中很多异常都会这样调用:
// 执行匿名函数
OpCase(i_apply_fun): {
BeamInstr *next;
SWAPOUT;
next = apply_fun(c_p, r(0), x(1), reg);
SWAPIN;
if (next != NULL) {
r(0) = reg[0];
SET_CP(c_p, I+1);
SET_I(next);
Dispatchfun();
}
goto find_func_info; // 遇到错误走这里
}
// 数学运算错误,或检查错误就会走这里
lb_Cl_error: {
if (Arg(0) != 0) { // 如果带了 label地址,就执行 jump指令
OpCase(jump_f): { // 这里就是 jump实现代码
jump_f:
SET_I((BeamInstr *) Arg(0));
Goto(*I);
}
}
ASSERT(c_p->freason != BADMATCH || is_value(c_p->fvalue));
goto find_func_info; // 遇到错误走这里
}
// 等待消息超时
OpCase(i_wait_error): {
c_p->freason = EXC_TIMEOUT_VALUE;
goto find_func_info; // 遇到错误走这里
}
好了,再看下 find_func_info 究竟是什么神通?
/* Fall through here */
find_func_info: {
reg[0] = r(0);
SWAPOUT;
I = handle_error(c_p, I, reg, NULL); // 获取异常错误指令地址
goto post_error_handling;
}
post_error_handling:
if (I == 0) { // 等待下次调度 erl_exit(),抛出异常中断
goto do_schedule;
} else {
r(0) = reg[0];
ASSERT(!is_value(r(0)));
if (c_p->mbuf) { // 存在堆外消息数据,执行gc
erts_garbage_collect(c_p, 0, reg+1, 3);
}
SWAPIN;
Goto(*I); // 执行指令
}
}
然后,简单看下 handle_error函数。
// erl_emu.c VM处理异常函数
static BeamInstr* handle_error(Process* c_p, BeamInstr* pc, Eterm* reg, BifFunction bf){
Eterm* hp;
Eterm Value = c_p->fvalue;
Eterm Args = am_true;
c_p->i = pc; /* In case we call erl_exit(). */
ASSERT(c_p->freason != TRAP); /* Should have been handled earlier. */
/*
* Check if we have an arglist for the top level call. If so, this
* is encoded in Value, so we have to dig out the real Value as well
* as the Arglist.
*/
if (c_p->freason & EXF_ARGLIST) {
Eterm* tp;
ASSERT(is_tuple(Value));
tp = tuple_val(Value);
Value = tp[1];
Args = tp[2];
}
/*
* Save the stack trace info if the EXF_SAVETRACE flag is set. The
* main reason for doing this separately is to allow throws to later
* become promoted to errors without losing the original stack
* trace, even if they have passed through one or more catch and
* rethrow. It also makes the creation of symbolic stack traces much
* more modular.
*/
if (c_p->freason & EXF_SAVETRACE) {
save_stacktrace(c_p, pc, reg, bf, Args);
}
/*
* Throws that are not caught are turned into 'nocatch' errors
*/
if ((c_p->freason & EXF_THROWN) && (c_p->catches <= 0) ) {
hp = HAlloc(c_p, 3);
Value = TUPLE2(hp, am_nocatch, Value);
c_p->freason = EXC_ERROR;
}
/* Get the fully expanded error term */
Value = expand_error_value(c_p, c_p->freason, Value);
/* Save final error term and stabilize the exception flags so no
further expansion is done. */
c_p->fvalue = Value;
c_p->freason = PRIMARY_EXCEPTION(c_p->freason);
/* Find a handler or die */
if ((c_p->catches > 0 || IS_TRACED_FL(c_p, F_EXCEPTION_TRACE))
&& !(c_p->freason & EXF_PANIC)) {
BeamInstr *new_pc;
/* The Beam handler code (catch_end or try_end) checks reg[0]
for THE_NON_VALUE to see if the previous code finished
abnormally. If so, reg[1], reg[2] and reg[3] should hold the
exception class, term and trace, respectively. (If the
handler is just a trap to native code, these registers will
be ignored.) */
reg[0] = THE_NON_VALUE;
reg[1] = exception_tag[GET_EXC_CLASS(c_p->freason)];
reg[2] = Value;
reg[3] = c_p->ftrace;
if ((new_pc = next_catch(c_p, reg))) { // 从进程栈上找到最近的 catch
c_p->cp = 0; /* To avoid keeping stale references. */
return new_pc; // 返回 catch end 指令地址
}
if (c_p->catches > 0) erl_exit(1, "Catch not found");
}
ERTS_SMP_UNREQ_PROC_MAIN_LOCK(c_p);
terminate_proc(c_p, Value);
ERTS_SMP_REQ_PROC_MAIN_LOCK(c_p);
return NULL; // 返回0,就是执行 erl_exit()
}
问题讨论
为什么 catch 要放在进程栈,然后利用立即数实现。
1、异常中断处理
erlang 本身就有速错原则,发生错误就会抛出异常,并 kill 掉进程。如果需要捕获异常,并获取中断处的结果,就要记录中断时要返回的地址。
2、catch 多层嵌套
因为 catch 允许多层嵌套结构,catch 里面的函数代码还可以继续再 catch,就无法用一个简单类型的变量表示。这需要一种数组或链表结构来表示 catch 层级的关系链。
问题延伸
进程堆与进程栈
至于 catch 实现为什么是进程栈,而不是进程堆,或者作为 VM 调度线程的变量?
首先,erlang VM 的基本调度单位是 erlang 进程。如果执行某段代码,就要有运行 erlang 进程来执行。为什么我们可以在 shell 下肆无忌惮地运行代码,实际上我们看到的是由 shell 实现进程执行后返回给我们的结果。
而 erlang 进程执行代码过程中产生的大多数数据会放到进程的堆栈上(ets,binary,atom 除外),而进程栈和进程堆是什么样的对应关系?
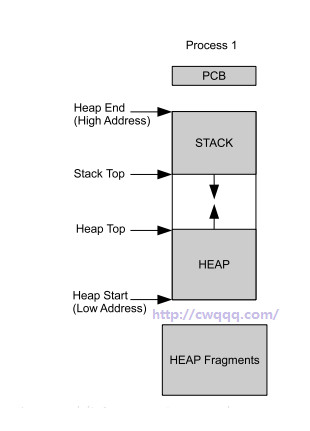
实际上,erlang 进程的栈和堆在 VM 底层实现上都是在 OS 进程/线程的堆上,因为 OS 提供的栈空间实在有限。
这里,低位地址表示了堆底,高位地址表示了栈底。中间堆顶和栈顶的空白区域,表示了进程堆栈还未使用到的空间,使用内存时就向里收缩,不够时就执行 gc
而 erlang 中,进程栈和进程堆的区别是栈只放入了简单的数据,如果是复杂数据,就只放头部(即前面最开始谈到的列表,boxed 对象),然后把实际的数据放到堆中。
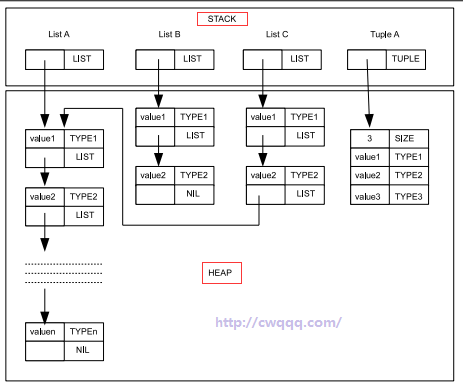
这里,尽管 VM 会把复杂数据存入 erlang 进程的堆上,但在栈上都保持了引用(或指针),但是,堆数据不会有引用(或指针)指向了栈。这么做,是为了减少GC的代价。这样,GC 时只要扫描结构较小的栈就可以,不用扫描整个堆栈。而进程字典写操作,就保留引用指向进程堆(暂时不讨论堆外数据的情况)
而这里,catch 实际表达的数据对象是一个 beam_catch_t 结构,最少最多也只能一个立即数表示,然后指向索引或指针位置。而且,catch 与进程运行上下文代码有关,允许多层嵌套,处理异常中断,如果像寄存器一样,作为 VM 调度线程的变量,将会引入更加复杂的设计
try-catch尾递归
try-catch语法结构内无法构成尾递归
t() -> try do_something(), t() catch _:_ -> ok end.
erlang 编译时会生成 try 和 try_end 指令,而这里 t() 实际就只是执行一次本地函数,不能构成尾递归。这点很好解释,感兴趣的同学可以打印汇编码探寻这个问题。同样的问题,catch 也存在。
erlang:hibernate
调用这个函数会使当前进程进入 wait 状态,同时减少其内存开销。适用场合是进程短时间不会收到任何消息,如果频繁收到消息就不适合了,否则频繁内存清理操作,也是不少开销。
但是,使用 erlang:hibernate 将会导致 catch 或者 try-catch 语句失效。
通过前面的内容可以知道,try catch 会往栈里面都压入了出错时候的返回地址,而 erlang:hibernate 则会清空栈数据,将会导致 try-catch 失效。
解决办法如下,参考proc_lib:hibernate的实现:
hibernate(M, F, A) when is_atom(M), is_atom(F), is_list(A) -> erlang:hibernate(?MODULE, wake_up, [M, F, A]). wake_up(M, F, A) when is_atom(M), is_atom(F), is_list(A) -> try apply(M, F, A) catch _Class:Reason -> exit(Reason) end.
2015/4/3 修改源码分析中 deallocate_return_Q 的说明