
原文 2015-06-03 20:02:28 发表于 CSDN,这里对以前写的文章做下收录。
erlang是开源的,很多人都研究过源代码。但是,从erlang代码到c代码,这是个不小的跨度,而且代码也比较复杂。所以这里,我利用一些时间,整理下erlang代码的执行过程,从erlang代码编译过程,到代码执行过程做讲解,然后重点讲下虚拟机执行代码的原理。
erlang代码编译过程
erlang对开发者是友好的,从erlang程序文件编译成能被erlang虚拟机识别的beam文件,在这个编译过程还对开发者暴露中间代码。借助这个中间代码,我们就可以逐步探究erlang代码的执行过程。
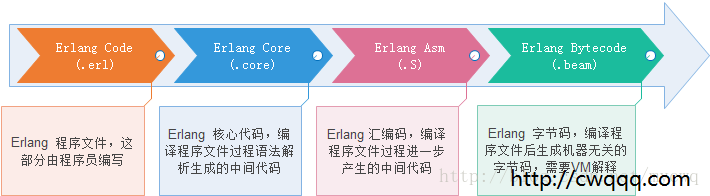
这是erlnag的编译过程,当然,最开始和大多数编译器一样,首先会将程序文件转换成语法树,但这个转换对我们来说阅读的意义不大,所以归结于以上3个过程。
1. erlang核心代码
确切的叫法是Core Erlang,使用了类似Haskell 的语法,每个变量都用“Let” 声明。在erlang shell通过以下方式可以获取模块的Core Erlang代码,将会生成test.core文件
c(test, to_core).
实际上core文件可以直接编译成beam文件,如下:
c(test, from_core).
2. erlang汇编码
这个是erlang代码编译成beam前的汇编代码,虽然在erlang打包成beam,以及加载到VM时会进一步优化,但汇编码实际上可以看成erlang代码到c代码的纽带。但理解汇编码而不是很容易,这里要知道erlang VM的设计基于寄存器,其中有两类重要的寄存器,传递参数的x寄存器,和在函数内用作本地变量的y寄存器。在erlang shell通过以下方式可以获取模块的汇编代码,将会生成test.S文件
c(test, to_asm). 或是 c(test, 'S').
当然,S文件也支持编译成beam文件,如下:
c(test, from_asm).
3. erlang BEAM
beam文件是不可阅读的,只是给VM识别,内容包括了代码,原子,导入导出函数,属性,编译信息等数据块。
4. erlang运行时代码
运行时代码是指模块加载到VM后的代码,erlang对开发者暴露了底层的接口。当模块加载后,在erlang shell下通过以下方式可以获取模块的运行时代码,就会生成test.dis文件
erts_debug:df(test).
这里,细心的同学会发现,通过对比erlang汇编码和运行时代码,发现指令代码是不完全相同的。一方面,erlang会对指令进一步做优化;另外,erlang使用了两种指令集,有限指令集和扩展指令集,在beam文件使用了有限指令集,然后在加载到VM时展开为扩展指令集。有论文说是为了减少Beam的大小,这点我没有做过实质性的探究,我只是觉得有限指令集比较短,更容易阅读被人理解。关于有限指令集和扩展指令集的差别,我在文章最后的拓展阅读做了讨论。
erlang代码从编译到执行过程
前面介绍了erlang代码编译的过程,现在再来说明erlang代码从编译到执行的完整过程。文章erlang版本以R16B02作说明。
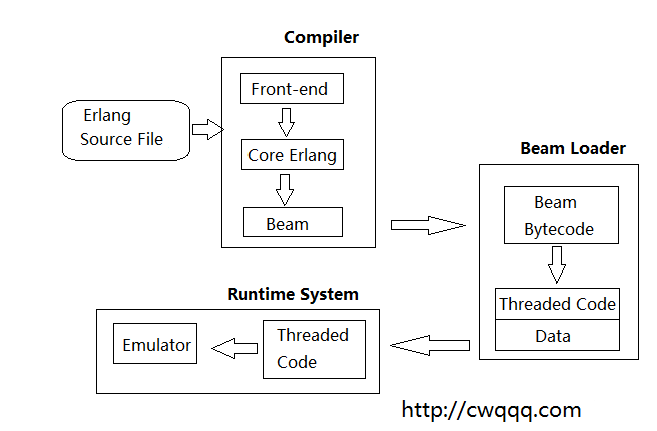
这里,erlang代码先被编译成beam,然后加载到VM中,最后再被模拟器所识别和调用。
其中,beam文件的加载过程会将beam的字节码形式的数据转成Threaded code和数据。前面也提到,beam文件的字节码数据包含有代码块,这里是将指令展开,转成Threaded code(线索化代码),每条指令包含了opcode(操作码)和operands(操作数),另外还对operands做修正,比如调用外部函数,这里会找到这个外部函数的导出地址,这样每次代码执行的时候就不用再去函数表查找到这个函数,就可以直接执行代码。
Beam的加载逻辑是在 beam_load.c 完成的,指令集的转换在beam_opcodes.c做了映射,而beam_opcodes.c文件是在编译Erlang源码过程有Perl脚本beam_makeops根据ops.tab生成的。所有有限指令集可以在genop.tab找到。
|
File
|
Path
|
|
beam_makeops
|
erts/emulator/utils/
|
|
ops.tab
|
erts/emulator/beam/
|
|
beam_opcodes.c
|
erts/emulator/
|
|
beam_load.c
|
erts/emulator/beam/
|
|
genop.tab
|
lib/compiler/src/
|
erlang 虚拟机执行代码的原理
这里先简单说明下erlang虚拟机、进程、堆栈,寄存器,然后侧重从指令调度,代码线索化说明虚拟机代码执行原理。
erlang虚拟机概述
通常我们说的eralng虚拟机,是指BEAM虚拟机模拟器和erlang运行时系统(ERTS)。ERTS是erlang VM最底层的应用,负责和操作系统交互,管理I/O,实现erlang进程和BIF函数。BEAM模拟器是执行Erlang程序经编译后产出的字节码的地方。
erlang虚拟机最早的版本是Joe Armstrong编写的,基于栈,叫JAM(Joe's Abstract Machine),很类似WAM(Warren's Abstract Machine)。后来改成基于寄存器的虚拟机,也就是现在的BEAM(Bogdan's Abstract Machine),执行效率有了较大幅度提升,这在Joe的erlang VM演变论文有说到。
基于栈和基于寄存器的虚拟机有什么区别?

基于栈(stack-based)的虚拟机的指令长度是固定的,执行多个操作数计算时,会先将操作数做压入栈,由运算指令取出并计算。而基于寄存器(register-based)的指令长度不是固定的,可以在指令中带多个操作数。这样,基于寄存器可以减少指令数量,减少入栈出栈操作,从而减少了指令派发的次数和内存访问的次数,相比开销少了很多。但是,如果利用寄存器做数据交换,就要经常保存和恢复寄存器的结果,这就导致基于寄存器的虚拟机在实现上要比基于栈的复杂,代码编译也要复杂得多
erlang进程
erlang进程是在代码执行过程中动态创建和销毁,每个进程都有自己私有的栈和堆。erlang进程是erlang虚拟机进行资源分配和调度的基本单位,erlang代码的执行要通过erlang进程来实现。
1> spawn(fun() -> m:loop() end).
<0.34.0>
或许有人会问,启动erlang节点时没有使用任何进程,这是为什么?实际上,启动erlang节点的代码是运行在shell进程,同样受到erlang虚拟机调度,我们看到的是由shell进程执行后返回的结果。
为了实现多进程并发,erlang虚拟机实现了进程挂起和调度机制。进程执行代码时会消耗调度次数(Reductions),当调度次数为0时就会挂起这个进程,然后从调度队列中取出第一个进程执行。如果进程在等待新消息时也会被挂起,直到这个进程接收到新消息后,就重新加到调度队列。
进程的栈和堆
erlang进程在执行代码的过程中,栈主要用来存放调用帧的本地变量和返回地址,堆则是用来存放执行过程创建的数据。在实现上,栈和堆是在同一个内存区域的。如下图:
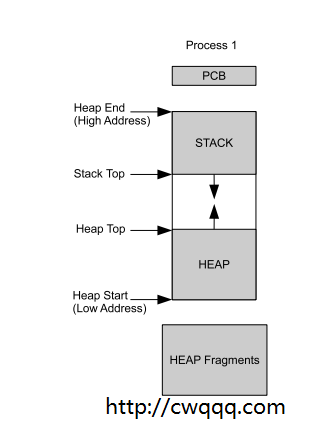
堆栈的内存空间是先申请一块较大的内存后一点一点使用,不够再重新申请一大块,这样避免频繁申请释放内存造成开销。以上,在已分配好的内存区域内,堆从最低的地址向上增长,而栈从最高的地址向下增长。中间堆顶和栈顶的空白区域,表示了进程堆栈还未使用到的空间,使用内存时就向里收缩,不够时就执行gc。这样,内存溢出检查就只要比较栈顶和堆顶就好。
堆用于存储复杂的数据结构,如元组,列表或大整数。栈被用来存储简单的数据,还有指向堆中复杂数据的数据指针。栈有指针指向堆,但不会有指针从堆到栈。
寄存器
前面也提到,对于基于栈的虚拟机,操作数在使用前都会被压到栈,计算时取出。也就是先将本地变量的值压入栈,然后在计算时从栈取出赋值给本地变量。所以,这里有很大开销在本地变量和栈之间的交换上(出入栈)。为此,基于寄存器的虚拟机使用临时变量来保存这个本地变量,这个临时变量也就是寄存器。而且,这个寄存器变量通常都被优化成CPU的寄存器变量,这样,虚拟机访问寄存器变量甚至都不用访问内存,极大的提高了系统的执行速度。
/*
* X register zero; also called r(0)
*/
register Eterm x0 REG_x0 = NIL;
register修饰符的作用是暗示编译器,某个变量将被频繁使用,尽可能将其保存在CPU的寄存器中,以加快其存储速度。随着编译程序设计技术的进步,在决定那些变量应该被存到寄存器中时,现在的编译器能比程序员做出更好的决定,往往会忽略register修饰符。但是就erlang虚拟机对寄存器变量的使用程度,应该是可以利用到CPU寄存器的好处。
erlang有哪些寄存器?
参数寄存器(R0-R1024) R0是最快的,是独立的寄存器变量,其他以reg[N]访问。R0还用来保存函数返回值
指令寄存器(IP) 引用当前正在执行的指令,可以通过I[N]取到上下文指令。
返回地址寄存器 (CP,原意Continuation Pointer) 记录当前函数调用的返回地址,在执行完当前函数后返回上一个函数中断处执行后面的代码。
栈寄存器(EP) 指向栈的栈顶,以E[N]数组形式访问栈帧数据
堆寄存器 (heap top)指向堆的堆顶,以HTOP[N]数组形式访问堆数据
临时寄存器(tmp_arg1和tmp_arg2)用于指令实现需要临时变量的场合(尽可能重用临时变量,同时利用CPU寄存器优化)
浮点寄存器(FR0-FR15)
其他寄存器:
'Live' 表示当前需要的寄存器数量,很多指令取这个值来判断是否要执行GC申请新的空间
'FCALLS' 表示当前进程剩余的调度次数(Reductions)
若不考虑多调度器,寄存器是所有进程共享的。当虚拟机调度运行某个进程的时候,寄存器就归这个进程使用。当进程被调出的时候,寄存器就给其他进程使用。(进程切换保存进程上下文时,只需要保存指令寄存器IP和当前函数信息,效率很高)
指令调度
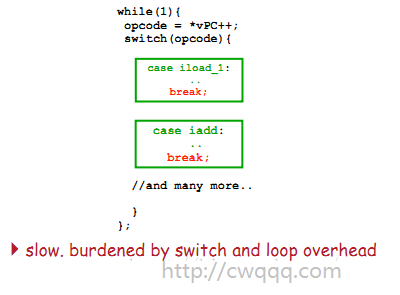
erlang指令调度实现是一个巨大的switch结构,每一个case语句都对应一个指令操作码(opcode),这样就可以实现指令的分发和执行。但是,switch调度方式实现简单,但效率比较低下。所以,erlang虚拟机使用了goto语法,避免过多的使用switch造成性能损耗;同时,erlang还使用跳转表,在一些高级编译器下(如GCC),利用label-goto语法,效率比较高(针对跳转表的概念,我之前也有文章说明,见这里)。正因为这点,虚拟机调度时解释指令的代价不容忽视,基于寄存器的虚拟机指令少,就要比基于栈高效。
while(1){
opcode = *vPC++;
switch(opcode){
case i_call_fun:
..
break;
case call_bif_e:
..
break;
//and many more..
}
};
字节码在虚拟机中执行,执行过程类似CPU执行指令过程,分为取指,解码,执行3个过程。通常情况下,每个操作码对应一段处理函数,然后通过一个无限循环加一个switch的方式进行分派。
erlang进程创建时必须指定执行函数,进程创建后就会执行这个函数。从这个函数开始一直到结束,进程都会被erlang虚拟机调度。
start()->
spawn(fun() -> fun1(1) end). %% 创建进程,执行 fun1/1
fun1(A) ->
A1 = A + 1,
B = trunc(A1), %% 执行 trunc/1
{ok, A1+B}.
以上,进程在执行函数( trunc/1)调用前,会将当前的本地变量和返回地址指针CP写入栈。然后,在执行完这个函数(trunc/1)后再从栈取出CP指令和本地变量,根据CP指针返回调用处,继续执行后面的代码。

这样,每次函数执行结束时,erlang从栈顶检查并取得CP指针(如果函数内过于简单,没有其他函数调用,就直接读取 (Process* c_p)->cp),然后将CP指针的值赋给指令寄存器IP,同时删除CP栈帧(根据需要还要回收Live借用的栈空间),继续调度执行。
备注:这里讲到的栈帧删除操作,如CP指针,本地变量数据,删除时只要将栈顶指针向高位移动N个位置,没有GC操作,代价极小。另外,这里也显露出一个问题,如果非尾递归函数调用,erlang需要反复将本地变量和CP指针入栈,容易触发GC和内存复制,引发内存抖动。
另外,在寄存器方面,函数调用时,erlang虚拟机会将传参写到参数寄存器x(N),然后更新返回地址寄存器CP,在函数调用返回时,会将返回值写到x(0)寄存器。
Threaded Code(线索化代码)
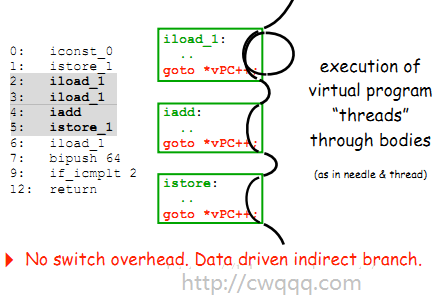
前面提到switch指令派发方式,每次处理完一条指令后,都要回到循环的开始,处理下一条指令。但是,每次switch操作,都可能是一次线性搜索(现代编译器能对switch语句进行优化, 以消除这种线性搜索开销,但也是只限于特定条件,如case的数量和值的跨度范围等)。如果是少量的switch case,完全可以接受,但是对于虚拟机来说,有着成百上千的switch case,而且执行频繁非常高,执行一条指令就需要一次线性搜索,确定比较耗性能。如果能直接跳转到执行代码位置,就可以省去线性搜索的过程了。于是在字节码的分派方式上,做了新的改进,这项技术叫作 Context Threading(上下文线索化技术,Thread目前都没有合适的中文翻译,我这里意译为线索化,表示其中的线索关系)。
这里取了Context Threading论文的例子,说明上下文线索化技术(Context Threading)
1.首先,代码会被编译成字节码
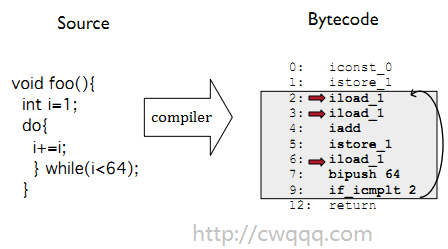
2.如果是switch派发指令,效率低下
3.如果是线索化代码(Threaded Code),就直接跳转(goto),无需多次switch
4.从字节码到最终执行代码的过程。
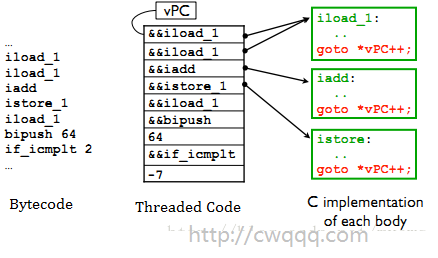
左边是编译生成的字节码,中间就是字节码加载后生成的线索化代码,右边是对应的虚拟机实现代码。虚拟机执行时,vpc指向了iload_1指令,在执行iload_1指令操作后根据goto *vpc++ 跳转到下一条指令地址,继续执行,如此反复。这个过程就好像穿针引线,每执行完一条指令,就直接跳转到下一条指令的地址,而不再是Switch Loop那样,每执行一条指令都要做一次switch。(这里,vPC是指虚拟PC指令,在erlang中是IP指针)
拓展阅读
BIF(内建函数)
BIF是erlang的内建函数,由C代码实现,用以实现在erlang层面实现效率不高或无法实现的功能。大多数BIF函数属于erlang模块,也有其他模块的BIF函数,ets或lists,os等
1> erlang:now().
{1433,217791,771000}
2> lists:member(1,[1,2,3]).
true
这里重点解释下,BIF代码如何被执行的。
erlang源代码编译时生成bif函数表信息,见 erts\emulator\
Export* bif_export[BIF_SIZE];
BifEntry bif_table[] = {
{am_erlang, am_abs, 1, abs_1, abs_1},
{am_erlang, am_adler32, 1, adler32_1, wrap_adler32_1},
{am_erlang, am_adler32, 2, adler32_2, wrap_adler32_2},
{am_erlang, am_adler32_combine, 3, adler32_combine_3, wrap_adler32_combine_3},
{am_erlang, am_apply, 3, apply_3, wrap_apply_3},
{am_erlang, am_atom_to_list, 1, atom_to_list_1, wrap_atom_to_list_1},
typedef struct bif_entry {
Eterm module;
Eterm name;
int arity;
BifFunction f; // bif函数
BifFunction traced; // 函数调用跟踪函数
} BifEntry;
erlang BEAM模拟器启动时会初始化bif函数表,
init_emulator:
{
em_call_error_handler = OpCode(call_error_handler);
em_apply_bif = OpCode(apply_bif);
beam_apply[0] = (BeamInstr) OpCode(i_apply);
beam_apply[1] = (BeamInstr) OpCode(normal_exit);
beam_exit[0] = (BeamInstr) OpCode(error_action_code);
beam_continue_exit[0] = (BeamInstr) OpCode(continue_exit);
beam_return_to_trace[0] = (BeamInstr) OpCode(i_return_to_trace);
beam_return_trace[0] = (BeamInstr) OpCode(return_trace);
beam_exception_trace[0] = (BeamInstr) OpCode(return_trace); /* UGLY */
beam_return_time_trace[0] = (BeamInstr) OpCode(i_return_time_trace);
/*
* Enter all BIFs into the export table.
*/
for (i = 0; i < BIF_SIZE; i++) { ep = erts_export_put(bif_table[i].module, //模块名 bif_table[i].name, bif_table[i].arity); bif_export[i] = ep; ep->code[3] = (BeamInstr) OpCode(apply_bif);
ep->code[4] = (BeamInstr) bif_table[i].f; // BIF函数
/* XXX: set func info for bifs */
ep->fake_op_func_info_for_hipe[0] = (BeamInstr) BeamOp(op_i_func_info_IaaI);
}
下面写个简单的例子说明,

bif函数编译后,opcode都是 call_bif_e,操作数是函数导出表地址,下面分析下这个opcode的实现:
/*
* 以下截取 bif 处理过程
*/
OpCase(call_bif_e):
{
Eterm (*bf)(Process*, Eterm*, BeamInstr*) = GET_BIF_ADDRESS(Arg(0)); // 根据参数获取bif实际执行函数
Eterm result;
BeamInstr *next;
PRE_BIF_SWAPOUT(c_p);
c_p->fcalls = FCALLS - 1;
if (FCALLS <= 0) { save_calls(c_p, (Export *) Arg(0)); } PreFetch(1, next); ASSERT(!ERTS_PROC_IS_EXITING(c_p)); reg[0] = r(0); result = (*bf)(c_p, reg, I); // 执行bif函数 ASSERT(!ERTS_PROC_IS_EXITING(c_p) || is_non_value(result)); ERTS_VERIFY_UNUSED_TEMP_ALLOC(c_p); ERTS_HOLE_CHECK(c_p); ERTS_SMP_REQ_PROC_MAIN_LOCK(c_p); PROCESS_MAIN_CHK_LOCKS(c_p); if (c_p->mbuf || MSO(c_p).overhead >= BIN_VHEAP_SZ(c_p)) {
Uint arity = ((Export *)Arg(0))->code[2];
result = erts_gc_after_bif_call(c_p, result, reg, arity);
E = c_p->stop;
}
HTOP = HEAP_TOP(c_p);
FCALLS = c_p->fcalls;
if (is_value(result)) {
r(0) = result;
CHECK_TERM(r(0));
NextPF(1, next);
} else if (c_p->freason == TRAP) {
SET_CP(c_p, I+2);
SET_I(c_p->i);
SWAPIN;
r(0) = reg[0];
Dispatch();
}
上面涉及到一个宏,就是取得bif函数地址。
#define GET_BIF_ADDRESS(p) ((BifFunction) (((Export *) p)->code[4]))
根据前面提到的,((Export *) p)->code[4] 就是 bif_table表的中BIF函数的地址。
扩展指令集
BEAM文件使用的是有限指令集(limited instruction set),这些指令集会在beam文件被加载时,展开为扩展指令集(extended instruction set)。
get_list -> get_list_rrx
get_list ->get_list_rry
call_bif -> call_bif_e
扩展指令集和有限指令集的差别是,扩展指令集还描述了操作数类型。
| Type | Description |
|---|---|
| t | An arbitrary term, e.g. {ok,[]} |
| I | An integer literal, e.g. 137 |
| x | A register, e.g. R1 |
| y | A stack slot |
| c | An immediate term, i.e. atom/small int/nil |
| a | An atom, e.g. 'ok' |
| f | A code label |
| s | Either a literal, a register or a stack slot |
| d | Either a register or a stack slot |
| r | A register R0 |
| P | A unsigned integer literal |
| j | An optional code label |
| e | A reference to an export table entry |
| l | A floating-point register |
以 call_bif_e 为例, e表示了操作数为函数导出表地址,所以 call_bif_e 可以这样取到bif代码地址
((Export *) Arg(0))->code[4]
文献资料:
[1] The Erlang BEAM Virtual Machine Specification Bogumil Hausman
[2] Virtual Machine Showdown: Stack Versus Registers Yunhe Shi, David Gregg, Andrew Beatty
[3] Context Threading: A flexible and efficient dispatch technique for virtual machine interpreters
[4] A Peek Inside the Erlang Compiler James Hague